Nagios
Que es Nagios
Nagios es uno de los sistemas de monitorización más extendidos del mundo. Opera en dos modos, pasivo y activo. ¿Que quiere decir esto? Los sistemas de monitorización intentan recabar información para saber si una máquina o servicio u otra información relevante sobre su estado. Que si el host no responde a PING, que si una web está caída o si le queda suficiente memoria a un host.
Checks en Nagios
Checkeos pasivos:
Se realizan median NRPE u otra aplicación externa como NSClient++ (para sistemas Windows).Estos agentes recogen información sobre el estado del sistema o servicio y la envían al servidor de Nagios de forma asíncrona, sin que Nagios tenga que hacer la solicitud.
Checkeos activos:
Son iniciados directamente por el servidor de Nagios, utilizando plugins propios o personalizados. Estos scripts realizan acciones como hacer una solicitud HTTP para verificar si una web responde con un código 200 OK, enviar un PING para comprobar si un host está activo, entre otros.
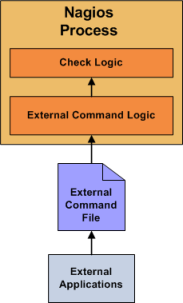
La documentación de la configuración puedes encontrarla en este enlace https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/3/en/configmain.html
Archivos clave de configuración
1
2
3
4
5
6
7
8
9
10
/usr/local/nagios/etc/nagios.cfg # Configuración principal del sistema.
/usr/local/nagios/etc/objects/hosts.cfg # Definición de [hosts]. Es recomendable crear un archivo por host
/usr/local/nagios/etc/objects/services.cfg # Definición de servicios.
/usr/local/nagios/etc/objects/commands.cfg: # Comandos.
/usr/local/nagios/etc/objects/contacts.cfg: # Información de notificaciones (emails, SMS, etc.).
nagios.cfg
Define que archivos deben incluirse en tu configuración y tambień es intersante las directivas de directorios para poder tener todo más organizado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# You can specify individual object config files as shown below:
cfg_file=/opt/nagios/etc/objects/commands.cfg
cfg_file=/opt/nagios/etc/objects/contacts.cfg
cfg_file=/opt/nagios/etc/objects/timeperiods.cfg
cfg_file=/opt/nagios/etc/objects/templates.cfg
# Definitions for monitoring the local (Linux) host
cfg_file=/opt/nagios/etc/objects/localhost.cfg
# You can also tell Nagios to process all config files (with a .cfg
# extension) in a particular directory by using the cfg_dir
# directive as shown below:
#cfg_dir=/opt/nagios/etc/servers
#cfg_dir=/opt/nagios/etc/printers
#cfg_dir=/opt/nagios/etc/switches
#cfg_dir=/opt/nagios/etc/routers
En Debian esto directorios tienen otra ruta /etc/nagios/objects/ la información anterior es por si lo instalas desde su instalador. Además puede que varíe la ruta de los plugins si usas otra distribución.
Plugins: Los plugins de Nagios son todos los programas o scripts encargado de realizar los checkeos.
Lógica de los checkeos
La lógica de Nagios se base en estos checkeos
Evalúa el estado según la información recibida mediante los Plugins:
- OK, Todo está bien, la web mostrará verde el objeto monitorizado
- WARNING, Problema detectado, en la web se verá amarillo, por ejemplo uso de cpu 85%
- CRITICAL o UNKNOWN. Problema detectado, se verá en rojo
Definir un host
Puedes definir cualquier máquina que tenga conectividad con tu servidor Nagios, impresoras, móviles, etc.
1
2
3
4
5
6
7
8
define host {
use generic-printer ; Inherit default values from a template
host_name hplj2605dn ; The name we're giving to this printer
alias HP LaserJet 2605dn ; A longer name associated with the printer
address 192.168.1.30 ; IP address of the printer
hostgroups network-printers ; Host groups this printer is associated with
}
Definir hostgroups
Se puede crear un archivo hostgroups.cfg para mantener grupos de hosts en Nagios
1
2
3
4
5
define hostgroup {
hostgroup_name network-printers ; The name of the hostgroup
alias Network Printers ; Long name of the group
}
Definir un servicio
Un servicio es una simple definición de que que host y que check se va a realizar para comprobar el estado del servicio. Además se puede definir que parámetros va a recibir dicho checkeo.
1
2
3
4
5
6
define service{
use local-service,graphed-service ; Name of service template to use
host_name localhost
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
Definición de comandos
Cada comando definido de esta manera donde se indica que script se va a utilizar y como se comportará según los resultados -w indica los ratios de warning, mientras que -c indica el crítico.
1
2
3
4
5
# 'check-host-alive' command definition
define command{
command_name check-host-alive
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 5
}
Definir contactos
Por defecto contacts.cfg, es el archivo donde se utiliza esta claúsula, también podemos disponemos de la claúsula contact group para hacer grupos de contacto, pero normalmente no es necesario. Se encarga de definir a quien avisarán las alertas, se puede definir desde correos electrónicos, pero se pueden usar de todo incluído bots de telegram para alertar.
1
2
3
4
5
6
7
8
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email nagios@localhost ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}
Los plugins de Nagios
Pongo la ruta en Docker => /opt/nagios/libexec pero en según que distro cambiará. Estos llamados plugins son scripts de checkeo de todo tipo, pero estos checkeos son checkeos activos. Por supuesto se pueden añadir plugins, tanto al agente como al host y en el foro de Nagios, github, etc podrás encontrar muchos gratuitos.
1
2
3
4
5
6
7
8
9
10
root@bcde5e5a33e4:/opt/nagios/libexec# ls
check-mqtt.py check_dig check_ftp check_imap check_mailq check_nntp check_oracle check_sensors check_ssmtp check_vpn
check_apt check_disk check_game check_ircd check_mem.pl check_nntps check_overcr check_simap check_swap check_wave
check_breeze check_disk_smb check_hpjd check_jabber check_mrtg check_nrpe check_pgsql check_smtp check_tcp mibs
check_by_ssh check_dns check_http check_jenkins check_mrtgtraf check_nt check_ping check_snmp check_time negate
check_clamd check_dummy check_icmp check_ldap check_mssql_database.py check_ntp check_pop check_spop check_udp remove_perfdata
check_cluster check_file_age check_ide_smart check_ldaps check_mssql_server.py check_ntp_peer check_procs check_sql check_ups urlize
check_dbi check_flexlm check_ifoperstatus check_load check_nagios check_ntp_time check_real check_ssh check_uptime utils.pm
check_dhcp check_fping check_ifstatus check_log check_ncpa.py check_nwstat check_rpc check_ssl_validity check_users utils.sh
Ejemplo de plugin, en realidad si analizamos el código de estos veremos que al final todo finalizan indicando una variable estado WARNING, CRITICAL, UNKNOWN, OK
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
#!/bin/sh
PROGNAME=$(basename "$0")
PROGPATH=$(echo "$0" | sed -e 's,[\\/][^\\/][^\\/]*$,,')
REVISION="2.4.12"
PATH="/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin"
export PATH
. "$PROGPATH"/utils.sh
print_usage() {
echo "Usage: $PROGNAME" [--ignore-fault]
}
print_help() {
print_revision "$PROGNAME" "$REVISION"
echo ""
print_usage
echo ""
echo "This plugin checks hardware status using the lm_sensors package."
echo ""
support
exit "$STATE_OK"
}
case "$1" in
--help)
print_help
exit "$STATE_OK"
;;
-h)
print_help
exit "$STATE_OK"
;;
--version)
print_revision "$PROGNAME" $REVISION
exit "$STATE_OK"
;;
-V)
print_revision "$PROGNAME" $REVISION
exit "$STATE_OK"
;;
*)
ignorefault=0
if test "$1" = "-i" -o "$1" = "--ignore-fault"; then
ignorefault=1
fi
sensordata=$(sensors 2>&1)
status=$?
# Set a default
text="SENSOR UNKNOWN"
exit=$STATE_UNKNOWN
if [ $status -eq 127 ] ; then
text="SENSORS UNKNOWN - command not found (did you install lmsensors?)"
exit=$STATE_UNKNOWN
elif [ "$status" != 0 ] ; then
text="WARNING - sensors returned state $status"
exit=$STATE_WARNING
elif echo "${sensordata}" | grep -q ALARM >/dev/null ; then
text="SENSOR CRITICAL - Sensor alarm detected!"
exit=$STATE_CRITICAL
elif [ $ignorefault -eq 0 ] && echo "${sensordata}" | grep -q FAULT >/dev/null; then
text="SENSOR UNKNOWN - Sensor reported fault"
exit=$STATE_UNKNOWN
else
text="SENSORS OK"
exit=$STATE_OK
fi
echo "$text"
if test "$1" = "-v" -o "$1" = "--verbose"; then
echo "${sensordata}"
fi
exit $exit
;;
esac
Nagios NRPE
Nagios NRPE (Nagios remote plugin executor). ¿Pues ya el nombre nos da una pista de lo que hace no? Este agente es capaz de ejecutar plugins en el host de forma remota,, permitiendo ejecutar estos plugins y recogiendo la información que de otra forma no sería factible, como por ejemplo el consumo de memoria o la carga de cpu.

Probar Nagios en Docker
Si quieres probar nagios y jugar con el un rato desde Docker puedes usar este comando, he incluído persistencia para tener acceso a los ficheros de configuración.
1
2
3
4
5
docker run --name nagios4 -p 0.0.0.0:8080:80 jasonrivers/nagios:latest # lanzamos una instancia de nagios
mkdir nagios # creamos una carpeta para la persistencia
docker cp nagios4:/opt/nagios/etc ./nagios/etc # copiamos los archivos de configuración
docker stop nagios4 # paramos el contenedor para volver a lanzarlo con persistencia
docker run --name nagios4 -p 0.0.0.0:8080:80 -v $PWD/nagios/etc:/opt/nagios/etc -d jasonrivers/nagios:latest
Después de hacer cambios en estos ficheros podrás reiniciar el contenedor con las configuraciones que hayas aplicado y/o reinciar el servicio de Nagios desde la propia interface web de Nagios (más rápido)
Si Nagios no arranca comprueba la configuración con este comando, seguramente te de una pista de que está pasando:
1
nagios -v /opt/nagios/etc/nagios.cfg

Como siempre estos post quedan sujetos a futuras modificaciones, correciones y/o mejoras pero como estoy probando Zabbix, otro sistema de monitorización quería dejar este post para el futuro.